Posted At: Mar 03, 2025 - 895 Views
Introduction
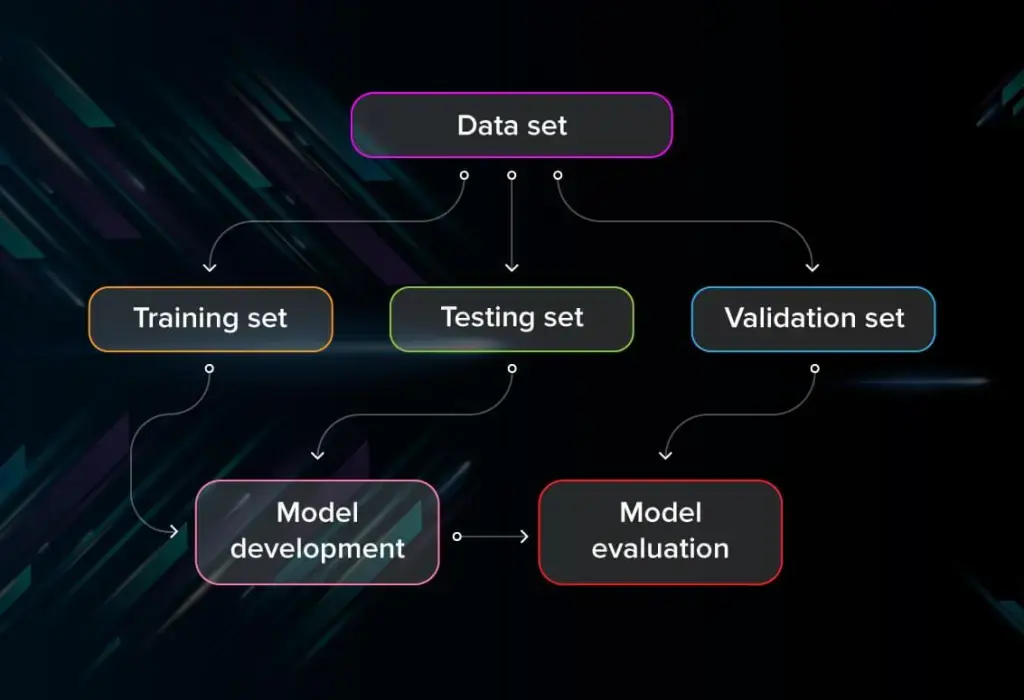
Data classification is a fundamental technique in machine learning and data mining, helping computers recognize patterns and make accurate predictions. Whether used for image recognition, spam filtering, or medical diagnostics, classification models rely on structured frameworks to ensure precision.
This discussion explores key insights into classification techniques, decision tree enhancements, hyperparameter tuning, and common model evaluation pitfalls, along with expert responses to critical questions in the field.
🚀 Download the Full Discussion (PDF): Click Here
1. What is Data Classification and Why Does It Matter?
📌 Key Insight: Data classification divides datasets into groups based on shared characteristics, enabling automation and decision-making.
🔹 Why Data Classification is Important:
✔ Enables computers to learn patterns for predictive modeling.
✔ Used in spam detection, fraud prevention, and medical analysis.
✔ Improves search accuracy, recommendation systems, and AI-driven decision-making.
🔹 Framework for Data Classification:
✔ Algorithm Selection: Choosing the best model for classification.
✔ Data Preprocessing: Cleaning and structuring data for accuracy.
✔ Training the Model: Teaching the algorithm using labeled datasets.
✔ Testing the Model: Evaluating its generalizability on new data.
💡 Takeaway: Effective classification models improve automation, efficiency, and predictive accuracy across industries.
2. Decision Trees and Their Modifications
📌 Key Insight: Decision trees provide a clear, interpretable structure for classification but require optimization techniques to improve performance.
🔹 How Decision Trees Work:
✔ Flowchart-based structure for making classification decisions.
✔ Splits data at each node based on attribute values.
✔ Final leaf nodes represent the class labels of the data.
🔹 Decision Tree Modifications:
✔ Pruning: Reduces complexity to prevent overfitting.
✔ Boosting: Combines multiple weak models into a stronger classifier.
💡 Strategic Insight: Decision trees are widely used in finance, healthcare, and cybersecurity, but require pruning and boosting for maximum efficiency.
3. Understanding Hyperparameters in Machine Learning
📌 Key Insight: Hyperparameters control model behavior and must be tuned carefully to optimize accuracy and efficiency.
🔹 Examples of Important Hyperparameters:
✔ Learning Rate: Controls how quickly a model updates weights.
✔ Tree Depth (for Decision Trees): Affects how deep a model can go before overfitting.
✔ Number of Estimators (for Boosting Models): Influences the model’s strength and accuracy.
🔹 Best Practices for Hyperparameter Tuning:
✔ Grid Search & Random Search: Automated methods for finding optimal values.
✔ Cross-Validation: Ensures hyperparameters generalize across datasets.
✔ Regularization Techniques: Prevents overfitting by penalizing excessive complexity.
💡 Takeaway: Fine-tuning hyperparameters improves model efficiency, reduces training time, and enhances prediction accuracy.
4. Common Pitfalls in Model Selection & Evaluation
📌 Key Insight: Overfitting and inaccurate evaluation metrics can lead to misleading machine learning results.
🔹 Major Challenges in Model Selection:
✔ Overfitting: Model performs well on training data but fails on real-world data.
✔ Imbalanced Datasets: Skewed data leads to biased predictions.
✔ Misleading Accuracy Scores: Accuracy alone is not enough—precision, recall, and F1-score must be considered.
🔹 How to Improve Model Evaluation:
✔ Cross-Validation: Ensures robustness by training on different subsets of data.
✔ Balanced Metrics: Use AUC-ROC, F1-score, and confusion matrices for better evaluation.
✔ Continuous Model Updating: Regularly retrain models with new data to maintain relevance.
💡 Best Practice: A well-evaluated model ensures high performance and real-world applicability.
5. Expert Discussion Response: The Four Types of Data Classification
📌 Question: What are the four types of data classification, and how are they defined?
🔹 Types of Data Classification:
✔ Supervised Learning: Uses labeled data to train models (e.g., spam detection).
✔ Unsupervised Learning: Identifies hidden patterns in unlabeled data (e.g., customer segmentation).
✔ Semi-Supervised Learning: Mixes labeled and unlabeled data for better accuracy.
✔ Reinforcement Learning: Uses rewards to train AI agents in dynamic environments.
💡 Expert Response: Each classification type serves different purposes in AI, ranging from structured predictions to discovering hidden insights in raw data.
6. Practical Applications of Data Classification & Model Evaluation
✔ Finance: Fraud detection models classify transactions as legitimate or fraudulent.
✔ Healthcare: AI systems predict disease diagnoses based on medical data.
✔ E-commerce: Recommender systems classify products based on customer preferences.
💡 Best Practice: A combination of robust classification models and proper evaluation techniques leads to more accurate AI-driven decision-making.
Conclusion
Data classification is crucial for modern AI applications, allowing businesses to categorize information, enhance automation, and improve predictive accuracy. Decision trees, hyperparameter tuning, and rigorous model evaluation help refine classification models for optimal performance in real-world scenarios.
📥 Download Full Discussion (PDF): Click Here
Related Machine Learning & Data Science Resources 📚
🔹 How Decision Trees Improve Machine Learning Models
🔹 The Role of Hyperparameter Tuning in AI Optimization
🔹 Best Practices for Evaluating Machine Learning Models
📌 Need expert guidance on AI, machine learning, and data classification? 🚀 Our professional writers at Highlander Writers can assist with AI research, algorithm optimization, and data science projects!
Leave a comment
Your email address will not be published. Required fields are marked *